Duplicate Content in SEO: Causes, Fixes and Best Practices
What is duplicate content in SEO?
The term duplicate content means the same (or very similar) content is on more than one webpage, most typically appearing on the same website in different places. As content is a core pillar in your marketing and SEO strategy, it is also one of the most important factors search engines take into consideration when ranking your website and its pages. SEO content duplication is therefore a bad practice that you should look to fix.
Benefits to Unique Website Content
Creating lots of good content helps to create a better overall experience on your website. In turn, here are some things you should expect to see as a result of detailed, focused and relevant content:
- Helpful to users of your website
- Improved target keyword rankings
- Decreased bounce rate
- More time spent on the website
- Higher conversion rate
Whilst this is not guaranteed, you should expect to see improvement in these core areas with unique content that matches search intent. Need some help revising and improving your content? Read our Content Pruning Guide for best practices on re-optimising your content.
Where Can Duplicate Content Appear?
It’s important to understand where and how duplicate content can appear on a website and what page elements will impact a website if duplicated. Here’s where to spot duplicate content.
Duplicate Content on the Same Website
Multiple URLs having the same content on the same website can cause issues for your rankings. The duplication can cause confusion to both search engines and the end user, deeming it not a helpful page. Confusion to a user can also result in clicking off the website as a whole (potentially increasing bounce rate and reducing average page duration) or service/eCommerce websites may see a reduction in conversions.
The new E-E-A-T Google guidelines states: “clearer guidance throughout the guidelines underscoring the importance of content created to be original and helpful for people, and explaining that helpful information can come in a variety of different formats and from a range of sources.” The webpage purpose is therefore to be relevant, helpful and people-first. When writing your content, you should take these things into consideration to be the most helpful to a user.
You can also have duplicate content unknowingly if both the www and non-www URL versions are available. If a user can access both webpages, this will be classed as the same content. This can also span to URLs with mismatched trailing slashes too. It is important to be consistent with your URL structure to avoid this duplication happening. If this has happened, you will need to use 301 redirects to fix this issue.
Duplicate Content Across Different Domains
When writing about a topic or copy for a landing page, you need to ensure your content is unique in the market. What happens, however, when this is done on an external domain?
Content Scraping
External duplicate content can come in two forms of content scraping:
- An external user taking website content and attempting to change the wording slightly – whether manually or using an AI tool, without adding any originality or extra value.
- Full content copy – a simple copy and paste of one website to another without asking permission or linking to the original content piece.
If you believe your content has been scraped by another website, you can request removal from the website owner directly by contacting them or file a DMCA report with Google for take down if that doesn’t work.
Content Syndication
Content Syndication is repurposing the same content across different domains as a marketing strategy, generating a bigger audience reach. Where this differentiates from content scraping is that it is an agreement between website owners which can include prominent disclaimers, links back to the original content, and use of canonical links.
An example of this is an agreed press release with another company. You may both upload the same press release for collaboration purposes, where the third party links to your website. However, before you agree to content syndication, you have to ensure it will be beneficial to your website and you will gain a degree of authority from it.
What Elements of a Webpage can Contain Duplicate Content?
The most obvious part of a webpage that can cause duplicate content issues is the main bulk of text on the page. This is a core focus in your strategy to make unique, although this also spans to more on page elements too.
Your H1: this is crucial for keyword optimisation – if you have multiple pages with the same H1, search engines will not know which page has the relevant information and they will be overlooked for that keyword ranking.

Metadata: for similar reasons, if you have multiple pages with the same meta title and meta description, this signals to search engines that this has duplicated page content and is not unique for a user.

What Elements of a Webpage are NOT Duplicate Content?
Some parts of a website can be reused and search engines will not take this into consideration. This can include your main navigation, website footer, and any valuable call to actions.

You may also have heard the term ‘boilerplate element’. Boilerplate content on a website is defined as parts of code/content that are reused and duplicated over multiple webpages with minimal to no change. These do not form the bulk of the content on the page, and search engines can often differentiate them.
How to Check for Duplicate Content on Your Website
Often, you may not have realised there’s duplicate content on your website, but this should be a dedicated part of website auditing. There are multiple ways you can determine the URLs and location of duplicate content, both manually and through tools.
Manual Auditing
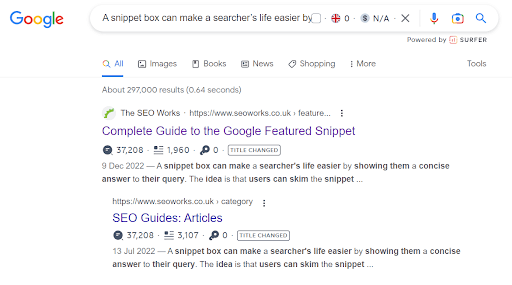
The easiest way to check for duplicate content is to put the main paragraph of the webpage content you have into Google and assess the search results. Here we have put into Google a main snippet of text from our Featured Snippet Guide and can see the top two search results are from the article (which is what you should expect to see). You can manually search through the results page. You may see some wording similarities, however, you want to assess how close the content is or if another page is ranking higher for that snippet of text.
Website Crawler Tools
If you have access to tools or website crawlers, there are often sections dedicated to full website analysis of duplicated content. Take the below snippet from Screaming Frog – you can see how many URLs, and how many exact duplicates or near duplicates there are. The same goes for Sitebulb too. These are useful for internal content only, alongside assessing duplicated metadata.

There are also a number of tools to access duplicated content information, some being free and some needing a premium subscription – for example, Grammarly’s plagiarism checker. There are however a number of plagiarism resources, so do your research and find one that works for you!
Is there a Google Duplicate Content Penalty?
No, there is not a specified Google duplicate content penalty. When a user makes that all important search, Google will determine which content is original. However, if your content is not original, your site can be penalised for malicious intent.
Duplicate content penalisation depends heavily on how the content is used. If it is used to simply copy another website or spam multiple pages to rank higher, naturally search engines can recognise this and penalise the rankings.
From ‘Demystifying the Duplicate Content Penalty’ – “Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.”
Ways to Remove Duplicate Content on Your Website
Some duplicate content is easier to fix but may be more time-consuming if you’re working with larger eCommerce websites. Here are some points to fix common duplicate mistakes:
Write Unique, Relevant, User-Centric Content
This goes without saying that duplicate content is best avoided by having unique content on each page of your website. You want to make it easy for a user to find what they need, when they need it, and offer value. If you have two similar pages, ask yourself, can the content be merged together to create one, highly-detailed page? Or are they two completely different topics that need to add their individual value?
Sometimes, this can be tricky. For example, if you’re not selling a unique product to your business only and multiple other outlets use the same manufacturer’s description. Whilst this is really relevant because the information has come from the manufacturer directly, you can still use the key points but add extra value. Think about additional points like when the product can be used, the product benefits, or any ways your expertise can showcase the relevancy of this product in search that sets it apart from other retailers’ content. Our Content Ideation Guide can help you think of fresh ideas!
Use Canonical Tags
A canonical tag (rel=canonical) tells search engines which page is the main version of duplicate or near duplicate pages. The main version of the page should be self-referential, with the other versions canonicalised to the master page.
An example of this is on an eCommerce site with the same product but different options of the products. For example, you may have a product page for a pair of shoes, but this same pair of shoes also has page versions for different size variations. You therefore want Google to understand which is the main page to index and rank, and which are user options/ variations of this same page. The description is the same, but the change is the option chosen.
This can also span into category pagination on a website too, where the URL structure can be /pagecategoryexample/page-2 and /pagecategoryexample/page-3. See our complete guide to URLs for SEO for more information.
Want an easy way to check if you need canonicals? Download our free flowchart:
Use 301 Redirects
If you have duplicate content that can not be sorted by changing the content or use of canonical tags, then it’s advised to use 301 redirects to the page you would like to be indexed. A 301 redirect is best practice as this is a permanent redirect signal for search engines and the user will automatically be sent to the end URL you have determined. This is helpful for search engines to understand and also to ensure the user finds the valuable information they’re looking for.
In Conclusion
In conclusion, make sure you set the bar high in your industry in terms of quality content and become familiar with the Google Quality Guidelines. Provide valuable, relevant information to the user about the product or service that cannot be found elsewhere. If duplicate content is necessary on your website, ensure the correct technical implementation is in place to not cause confusion and disrupt your organic rankings!

Beth is a Senior Account Executive with a background in the full digital marketing mix. She is passionate about creating content strategies to drive site engagement!

